ResDiary AU Azure Migration

In this post, I want to describe a recent lift and shift migration into Azure that we performed at ResDiary, specifically describing the process we used to ensure that the migration was successful first time. I’m not going to go into great depth about technical details, partly to keep this post as concise as possible, and partly because I want my team members, Paul and Lewis, to write their own posts.
Our overall goal was to take an existing web application (we call it the diary application) running in a dedicated data centre in Australia, and move it into Azure. The application consisted of an IIS web site and an SQL Server database cluster, looking something like this:
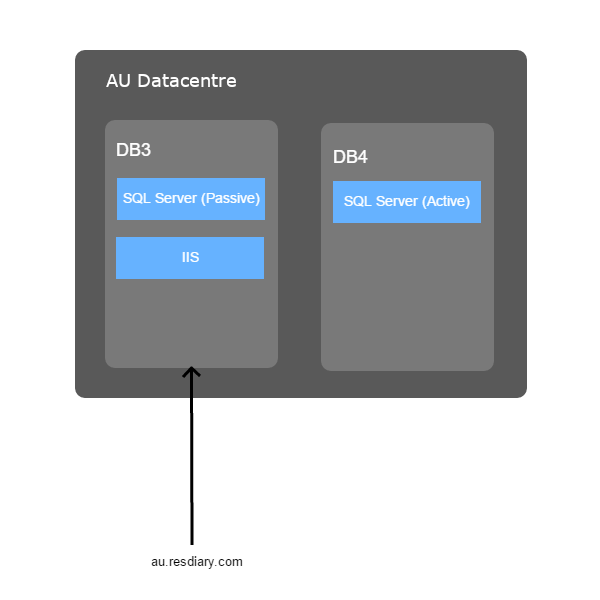
Our aim for the migration was to end up with this:
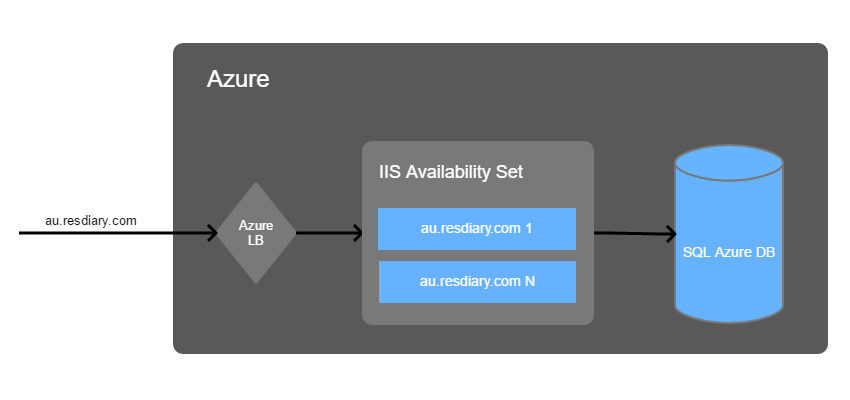
Planning
The first stage was to come up with a rough plan for the migration process:
- Setup the Azure infrastructure we would need, including an SQL Azure database, load balancer, and virtual machines to run IIS.
- Replicate the database to Azure using Transactional Replication.
- Stop the replication, and shift the traffic over to Azure.
Once we had our plan in place, we came up with potential issues we might face, and how we could solve them. The main issues I want to highlight are:
- Dealing with the DNS propagation delay when moving the traffic to Azure.
- How we could quickly switch back in the case of a failed migration.
- How to verify that our new environment was working correctly, and could handle the volume of traffic we receive in production.
To deal with the first two points, we temporarily inserted an intermediate load balancer between our customers and our existing data centre. Initially this load balancer just sent all the traffic to the existing system, but what it meant was that we could instantly switch over to Azure and back without waiting for DNS records to propagate:
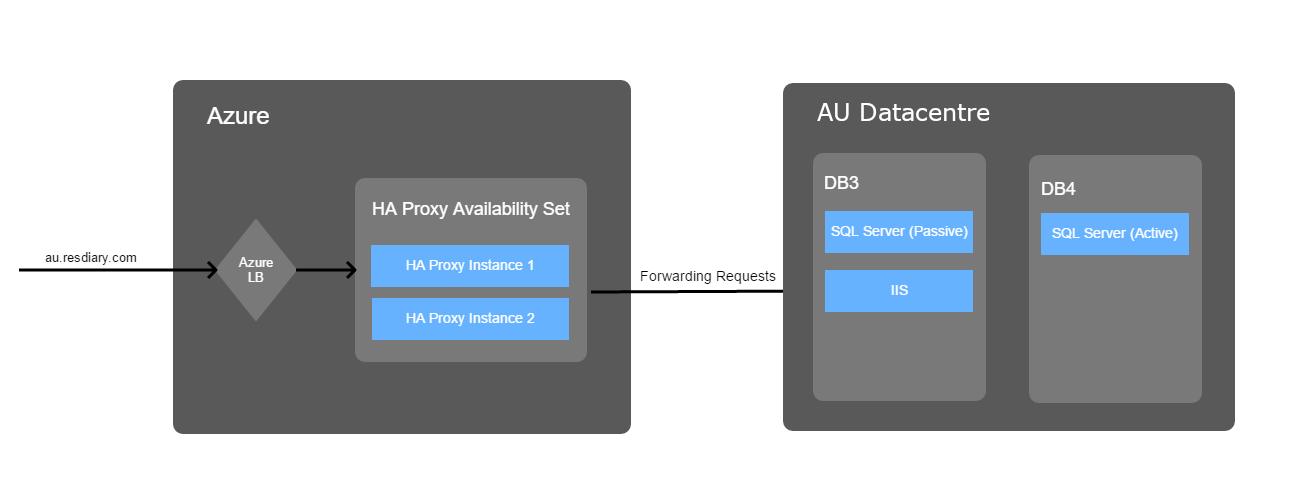
One possible issue with this was that it could have added unnaceptable latency onto our requests since all the traffic was being routed through an extra machine in a different data centre. To combat this, we chose the Azure region that was closest to our existing data centre, and we also ran several tests comparing going via the load balancer vs going directly to the backend servers. We found that the latency difference was small enough that we didn’t think it would cause issues.
Load Testing
Routing the traffic through these intermediate machines also allowed us to run Go Replay to solve the problem of ensuring that our new environment could handle our production traffic.
Go Replay is a tool that allows you to capture raw HTTP traffic, and replay it against a different set of servers. What this meant was that we could run our real production traffic against our new servers, and ensure that the virtual machines, database, and other components were all configured correctly, and that they were able to handle our volume. The reason I wanted to try using Go Replay is that it would give us certainty that our Azure environment could handle our real traffic, rather than trying to manufacture an artificial load test that would have been an educated guess at best.
We setup Go Replay on our HA Proxy load balancers, and mirrored the traffic to an Azure Load Balancer that our Azure IIS VMs sat behind:
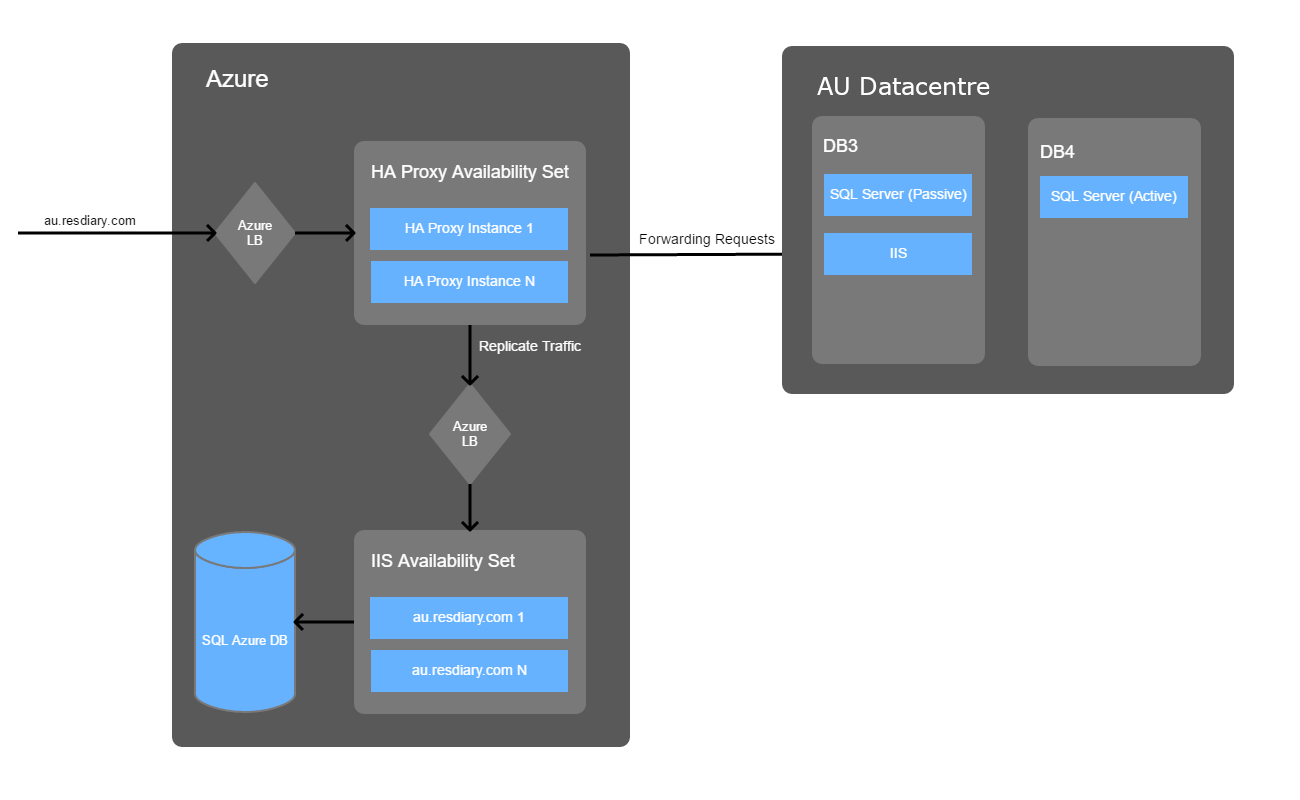
The traffic to this particular system follows a predictable pattern: we are quietest on Mondays with the traffic steadily increasing throughout the week to peak on Friday and Saturday evenings. Because of this, we aimed to run the following set of tests at a minimum:
- An initial test that ran for around an hour starting at 01:00 AEST. This allowed us to confirm our testing methodology worked, that it didn’t impact our production traffic, and to make any adjustments necessary.
- A longer test during our peak time (roughly 15:00 until 21:00 AEST), but early in the week when traffic volumes were lower.
- A test over a full day on a Friday to capture our busiest period.
After each test, we wrote up a report comparing various metrics between our production and Azure systems. This included (but wasn’t limited to):
- CPU load.
- Memory usage.
- Requests per second.
- Error rates.
Based on the results of each test, we adjusted our Azure infrastructure as necessary, wiped our Azure SQL database, and then replicated it again to get it ready for the next set of tests.
Disabling Side-Effects
As with most complex web applications, our diary application doesn’t sit in total isolation,and performing actions like creating bookings can cause side-effects. These include sending confirmation emails and SMS messages, and making API calls to third party systems as well as other parts of ResDiary.
Since we were mirroring production traffic, we were particularly concerned about accidentally sending duplicate booking confirmations to customers, or making duplicate payments. We used two main approaches to solve this:
- Feature toggling the parts of the system that cause side-effects, and disabling them for the load tests.
- Using a blanket
Deny Allfirewall rule on all outbound connections except those going to our SQL Azure database, our monitoring systems, etc.
What you need to bear in mind when doing this is that it has an effect on the results of your load tests. For example, disabling certain pieces of functionality via feature toggling can cause your application to do less work, and for certain requests to complete much faster than they normally would. Firewall rules can cause timeouts that wouldn’t normally occur, making it seem like the new system is performing more poorly than it actually is.
As a result, we assumed that the figures from our load testing were not going to be completely accurate, and we deliberately over-provisioned the infrastructure in Azure to accommodate this. Now that we’ve been able to take a look at the figures after performing the migration, I would estimate that we saw around a 5-10% increase in CPU usage compared to our load tests, which was well within our margin of error.
Migration Checklist
Once we were happy that the testing had gone well, and that we had a very good idea of the process involved in migrating, we put together a checklist that we used when actually running the migration. This detailed any steps we needed to take in the days leading up to the migration, at the time of the migration, and anything we needed to do afterwards to clean up temporary infrastructure that had just been created to facilitate the load testing.
We also set a time limit for the point where there was no going back, and a few checkpoints before that time with details of how to rollback if neccessary at various points in time. This meant that if we had been faced with an emergency situation, we could just follow the plan we’d previously agreed instead of wasting time trying to decide what to do.
Conclusion
When it came time to switch over to Azure, I was nervous, but I also felt like we had done a good job of testing the migration process itself (by virtue of running several sets of tests), and proving that the new environment could handle the traffic. So far, we’ve made it through an entire week, including Friday and Saturday nights, without any reported issues, and with the new Azure environment behaving well within its limits.
In closing, I would like to thank the rest of the ResDiary development team for supporting us during this migration, and specifically my team members Lewis and Paul who worked closely with me on this project. As I mentioned before, I’ve asked them to write up more detailed descriptions of some of the technical challenges we faced, so keep an eye out for future posts from the ResDiary Product Team.
I would also like to thank Raphael and Guillaume from our parent company, Accor, who reviewed the plan with me before we started the project, and gave me valuable feedback on it.